
정보 기준일: 2026년 3월 14일 — Perplexity 공식 블로그, Changelog, TechCrunch 등의 공개 자료를 기반으로 작성했습니다.
“구글에 검색하면 링크 10개가 나오고, AI에게 물어보면 출처가 불분명한 답이 나온다.” 이런 경험이 있을 거다. 물론 ChatGPT도 웹 검색 기능을 도입했고, Google도 AI Overviews를 제공하고 있습니다. 하지만 Perplexity AI는 처음부터 “실시간 웹 검색 + 출처 인용”을 핵심 설계 원칙으로 만들어진 AI 검색엔진입니다. 질문하면 웹을 실시간으로 뒤져서, 모든 문장에 클릭 가능한 출처가 달린 요약 답변을 돌려줍니다.
이 글에서는 Perplexity가 내부적으로 어떻게 작동하는지, 어떤 AI 모델들을 사용하는지, 그리고 어떻게 써야 가장 효과적인지를 객관적 데이터와 공식 출처를 기반으로 정리합니다.
1. Perplexity AI는 어떻게 작동하는가? — RAG 파이프라인 해부
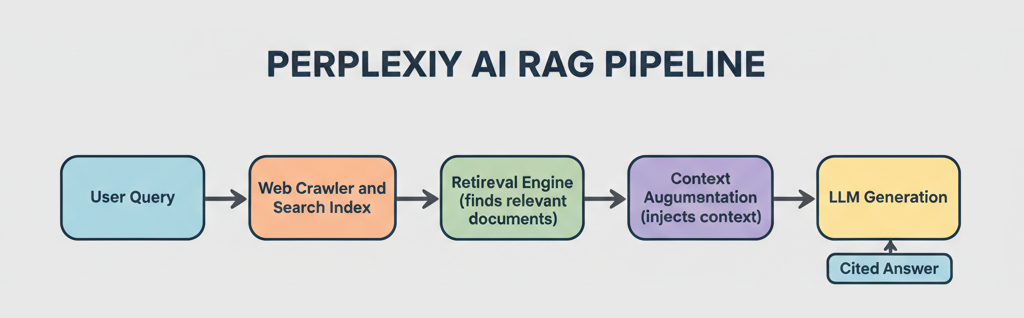
Perplexity의 RAG 파이프라인 — 검색(Retrieval), 증강(Augmentation), 생성(Generation) 3단계
문제: 기존 AI의 한계
ChatGPT 같은 LLM(Large Language Model, 대규모 언어 모델)은 학습 데이터에 갇혀 있습니다. “오늘 날씨”를 물어보면 2024년 이전 데이터로 대답하려 하죠. 반대로 구글 검색은 최신 정보는 있지만, 링크 목록을 던져줄 뿐 요약해주지 않습니다.
원인: LLM은 “기억”에 의존한다
기본적으로 LLM은 학습 시점까지의 정보만 “기억”합니다. 이걸 지식 단절(Knowledge Cutoff)이라고 부릅니다. 2025년에 학습이 끝난 모델에게 2026년 소식을 물어봐도 답할 수 없는 구조적 한계입니다.
해결: RAG(Retrieval-Augmented Generation) 파이프라인
Perplexity는 이 문제를 RAG라는 기술로 풀었습니다. RAG를 쉽게 비유하면 이렇습니다:
🍳 비유: 오픈북 시험을 생각해보세요. 학생(LLM)이 시험을 보는데, 교과서(웹 검색 결과)를 옆에 펼쳐놓고 참고하면서 답안을 작성하는 겁니다. 기억에만 의존하는 클로즈드북 시험(일반 LLM)과는 정확도가 다를 수밖에 없죠.
Perplexity의 RAG 파이프라인은 3단계로 구성됩니다:
1단계 — 검색(Retrieval)
사용자가 질문을 입력하면, Perplexity의 자체 검색 엔진이 웹을 실시간으로 크롤링합니다. Perplexity 공식 기술 블로그에 따르면, 수만 개의 CPU와 수백 TB의 RAM을 사용하는 엑사바이트(Exabyte) 규모의 ML 최적화 인덱스를 운용합니다. 단순 키워드 매칭이 아닌, 의미 기반(Semantic) + 키워드 기반(Lexical) 하이브리드 검색을 수행합니다.
2단계 — 증강(Augmentation)
검색된 문서 스니펫(snippet, 문서의 핵심 조각)을 LLM의 컨텍스트에 주입합니다. 최대 200,000 토큰(약 15만 단어 분량)의 문맥을 한 번에 처리할 수 있습니다. 이 과정에서 여러 출처를 교차 대조하는 자동 팩트체킹이 이루어집니다.
3단계 — 생성(Generation)
증강된 컨텍스트를 바탕으로 LLM이 답변을 생성합니다. 이때 인라인 인용(Inline Citation)이 자동으로 붙어서, 답변의 각 문장이 어디서 온 정보인지 클릭 한 번으로 확인할 수 있습니다.
핵심 차별점: Perplexity는 단일 모델에 의존하지 않습니다. 질문의 종류, 복잡도, 사용자의 구독 플랜에 따라 가장 적합한 LLM을 자동 라우팅하는 독자적인 시스템을 갖추고 있습니다.
출처: Perplexity 공식 기술 블로그 “Architecting and Evaluating an AI-First Search API” (research.perplexity.ai), DataStudios 분석 (2025년 12월)
2. Perplexity의 모델 생태계 — 무엇이 답변하고 있는가?
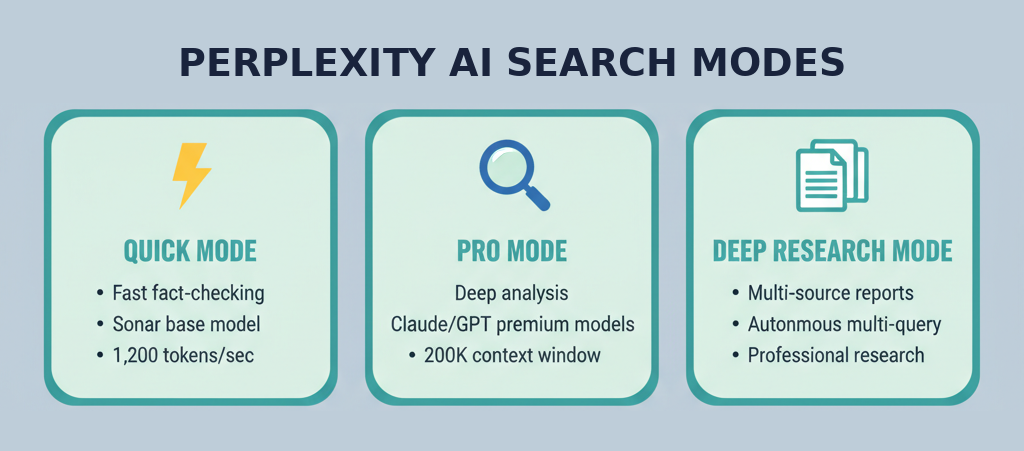
Perplexity의 검색 모드별 특징 비교
Perplexity를 쓸 때 가장 중요한 건 “지금 어떤 모델이 내 질문에 답하고 있는가”를 이해하는 것입니다. Perplexity는 자체 모델과 외부 모델을 혼합 운용합니다.
2.1 자체 모델: Sonar 패밀리
Perplexity가 2025년 2월에 출시한 자체 모델 라인입니다. Meta의 Llama 3.3 70B를 기반으로 검색 최적화 훈련을 추가한 모델입니다.
성능 비교: Perplexity 공식 벤치마크에 따르면, Sonar는 GPT-4o mini와 Claude 3.5 Haiku보다 사용자 만족도 A/B 테스트에서 더 높은 점수를 받았습니다. 특히 응답 속도 면에서 Cerebras 인프라 기반 초당 1,200 토큰은 Gemini 2.0 Flash 대비 약 10배 빠른 수준입니다.
출처: Perplexity 공식 블로그 “Meet New Sonar” (2025.02.11), TechCrunch “Perplexity launches Sonar API” (2025.01.21)
2.2 외부 프리미엄 모델 (Pro/Max 구독자용)
Pro 구독자는 Perplexity 앱 내에서 다음 외부 모델을 직접 선택할 수 있습니다:
“Best” 모드를 선택하면 Perplexity의 자동 라우터(Router, 질문 유형에 따라 최적 모델을 선택하는 시스템)가 질문에 가장 적합한 모델을 알아서 골라줍니다.
2.3 검색 모드별 모델 배정
출처: DataStudios “Perplexity AI All Available Models” (2025.12), Perplexity 공식 Help Center
3. 2026년 최신 기능 업데이트
Perplexity는 2026년 초에 대규모 기능 업데이트를 단행했습니다. 핵심 변화를 정리합니다.
Model Council (2026년 2월)
여러 프론티어 모델(Claude Sonnet 4.6, Gemini 3.1 Pro, Opus 4.6 등)을 동시에 실행하여 합의점과 불일치점을 종합합니다. 전문 리서치에서 교차 검증이 필요한 경우에 유용합니다.
비유: 한 명의 전문가 의견 대신, 여러 전문가 패널의 합의를 받는 것과 같습니다.
Deep Research 업그레이드 (2026년 2월 6일)
Pro/Max 사용자 전용으로 강화된 Deep Research 모드가 출시되었습니다. 자체 검색 인프라와 샌드박스 환경에서 최고 수준의 추론 모델이 보고서급 결과물을 생성합니다.
Perplexity Computer (2026년 2월 27일)
19개 AI 모델을 에이전트(Agent, 자율적으로 작업을 수행하는 AI 시스템) 방식으로 오케스트레이션하여 복잡한 워크플로우를 처리합니다. 예를 들어, “경쟁사 분석 보고서 작성 → 슬라이드 생성 → 이메일 초안 작성”과 같은 다단계 작업을 자동화할 수 있습니다.
Comet 브라우저 (2026년 2월 27일)
AI 기반 브라우저로, 음성 모드(GPT Realtime 1.5 기반), 멀티탭 자동화, 화면 상호작용 기능을 갖추고 있습니다. Max 구독자에게 우선 접근권이 부여됩니다.
출처: Perplexity Changelog (2026.02.06, 2026.02.27), TechCrunch (2026.02.27), DataStudios (2026.03)
4. 요금제 비교 — 무료 vs Pro vs Max
판단 기준:
– 가벼운 사용: 무료로도 하루 3~5회 Pro 검색이 가능합니다.
– 업무/학습 용도: Pro($20/월)가 가성비 최적. 매일 300회 이상 Pro 검색 + 프리미엄 모델 접근.
– 헤비 유저/전문가: Max($200/월)는 무제한 Deep Research + 최고급 모델(Opus, o3-pro) 접근.
출처: Perplexity 공식 요금제 페이지 (perplexity.ai/pro, perplexity.ai/enterprise/pricing), Finout “Perplexity Pricing in 2026” 분석
5. Perplexity vs ChatGPT vs Google — 객관적 비교
상황별 추천 도구 — Perplexity vs ChatGPT vs Google
어떤 도구를 쓸지 고르려면 각각의 강점과 약점을 알아야 합니다. 2025년 벤치마크 데이터를 기반으로 비교합니다.
아래 비교는 2025년에 수행된 벤치마크(Cension AI 블라인드 테스트: 일반 지식 100문항, WordStream PPC 도메인 200문항)를 인용합니다. 테스트 조건과 도메인에 따라 결과가 달라질 수 있으므로 참고용으로 활용하세요.
핵심 인사이트:
– 팩트 체크/리서치: Perplexity가 가장 우수. 출처 투명성이 핵심 차별점.
– 창의적 작업/코딩: ChatGPT(GPT-4/5)가 더 적합.
– 일상적 정보 (날씨, 맛집): Google이 Knowledge Graph 기반으로 여전히 강함.
출처: Cension AI 블라인드 테스트 (2025), WordStream PPC 정확도 연구 (2025.07), Skywork AI 비교 분석 (2025), Forrester 환각 분석
6. Perplexity를 최대한 활용하는 7가지 팁
팁 1: 질문 유형에 맞는 모드를 선택하세요
팁 2: 포커스 모드로 검색 범위를 좁히세요
Perplexity는 검색 범위를 지정하는 포커스 모드(Focus Mode)를 제공합니다:
– 웹 전체: 일반 검색 (기본값)
– 학술(Academic): 논문, 연구 자료만 검색
– Reddit: 커뮤니티 의견, 실사용 후기
– YouTube: 영상 트랜스크립트 기반 검색
– Writing: 글쓰기 도우미 모드
예를 들어, “React Server Components의 성능 벤치마크”를 찾을 때 학술 모드로 검색하면, 블로그 대신 논문과 공식 벤치마크 자료가 우선적으로 검색됩니다.
팁 3: 맥락(Context)을 충분히 제공하세요
❌ "파이썬 에러 해결해줘"
✅ "Python 3.12에서 FastAPI를 사용 중인데, Pydantic v2로 마이그레이션하면서
ValidationError가 발생합니다. 기존 코드는 model_validator를 사용하고 있고,
에러 메시지는 'field required'입니다. 해결 방법을 알려주세요."
맥락이 구체적일수록 검색 쿼리가 정확해지고, 더 관련성 높은 출처를 찾아줍니다.
팁 4: 스레드(Thread)를 활용해 깊이 파고드세요
Perplexity의 대화형 스레드는 이전 질문의 맥락을 유지합니다. 하나의 주제에 대해 후속 질문을 이어가면, Perplexity가 자동으로 관련 질문(Related Questions)을 추천해줍니다.
1차 질문: "Docker Compose란 무엇인가요?"
2차 질문: "이걸 Kubernetes와 비교하면 어떤 차이가 있나요?"
3차 질문: "소규모 프로젝트에서는 어떤 걸 쓰는 게 나을까요?"
대안 도구: Docker Compose 대신 Podman Compose도 사용 가능합니다. Kubernetes 대안으로는 k3s(경량 쿠버네티스)가 있습니다.
팁 5: 파일 업로드로 문서 분석을 시키세요
Pro 이상 구독자는 PDF, 스프레드시트, 코드 파일 등을 업로드하여 AI가 분석하게 할 수 있습니다. 예를 들어, 100페이지짜리 기술 문서를 업로드하고 “이 문서의 핵심 내용을 5가지로 요약해줘”라고 요청하면, 문서 내용과 웹 검색 결과를 함께 참고한 답변을 받을 수 있습니다.
팁 6: API를 활용해 자체 서비스에 통합하세요
Perplexity는 Sonar API를 통해 개발자가 자신의 서비스에 AI 검색을 통합할 수 있게 합니다.
# Perplexity Sonar API 사용 예시 (OpenAI SDK 호환)
from openai import OpenAI
client = OpenAI(
api_key="발급받은_키",
base_url="https://api.perplexity.ai"
)
response = client.chat.completions.create(
model="sonar-pro", # 또는 "sonar", "sonar-reasoning-pro"
messages=[
{"role": "system", "content": "정확한 정보를 출처와 함께 제공해주세요."},
{"role": "user", "content": "2026년 AI 검색 시장 동향"}
]
)
print(response.choices[0].message.content)
참고: OpenAI SDK와 호환되므로, 기존 OpenAI 코드에서
base_url만 바꾸면 바로 사용할 수 있습니다. 별도의 Perplexity 전용 SDK 설치가 필요 없습니다.
Sonar API 가격 (2025년 기준):
– Sonar (기본): 저비용, 빠른 검색
– Sonar Pro: 검색당 $5/1,000회 + 입력 $3/100만 토큰 + 출력 $15/100만 토큰
– 인용 토큰 무과금: Pro/Reasoning Pro에서 인용 부분은 요금에서 제외
팁 7: Model Council로 중요한 의사결정을 검증하세요
중요한 리서치에서는 Model Council 기능을 활용하세요. 여러 AI 모델이 같은 질문에 독립적으로 답하고, 합의점과 불일치를 정리해줍니다. 이를 통해 특정 모델의 편향(bias)이나 환각(hallucination)을 걸러낼 수 있습니다.
7. Sonar API 상세 스펙 — 개발자를 위한 정보
개발자가 Sonar API를 평가할 때 필요한 핵심 스펙입니다:
출처: Perplexity 공식 API 문서 (docs.perplexity.ai), Perplexity 공식 블로그 “New Sonar Search Modes” (2025)
8. 알아둬야 할 한계점과 주의사항
어떤 도구든 만능은 아닙니다. Perplexity를 사용할 때 알아둬야 할 점들입니다.
정확도의 한계
– Perplexity도 환각(Hallucination)에서 완전히 자유롭지 않습니다. 출처가 달려 있더라도, 해당 출처의 내용을 잘못 요약하거나 맥락을 벗어나 인용하는 경우가 있습니다.
– 속보나 방금 발생한 이벤트는 검색 인덱스에 아직 반영되지 않을 수 있습니다.
프라이버시 고려사항
– 무료/Pro 플랜의 경우, Perplexity의 데이터 처리 정책을 확인하세요. Enterprise 플랜은 “사용자 데이터로 모델을 학습하지 않음”이 명시되어 있지만, 일반 플랜은 서비스 개선 목적으로 쿼리가 활용될 수 있습니다.
– 민감한 업무 정보를 입력할 때는 Enterprise 플랜을 고려하거나, Sonar API를 통한 직접 연동을 권장합니다. API는 공식적으로 고객 데이터를 학습에 사용하지 않습니다.
언어별 성능 차이
– 영어 쿼리에 비해 한국어 쿼리의 검색 정확도와 출처 다양성이 떨어질 수 있습니다. 중요한 리서치는 영어와 한국어를 병행하여 검색하는 것을 권장합니다.
경쟁 대안
– Perplexity 외에도 You.com(개인정보 보호 강조), Bing Copilot(Microsoft 생태계 통합), SearchGPT(OpenAI의 검색 기능) 등 AI 검색 도구가 있습니다. 용도와 환경에 맞는 도구를 선택하세요.
마무리: 어떤 상황에서 Perplexity를 써야 할까?
Perplexity AI는 “AI 검색엔진”이라는 새로운 카테고리를 만들어가고 있습니다. 기존 검색 엔진의 실시간성과 LLM의 종합 능력을 결합한 이 접근법은, 특히 팩트 기반의 정확한 정보가 필요한 상황에서 가장 빛을 발합니다.
이 글의 핵심 정리:
– Perplexity는 RAG 파이프라인(검색→증강→생성)으로 실시간 웹 정보를 LLM에 주입하여, 출처가 달린 답변을 생성합니다.
– 자체 Sonar 모델 패밀리와 외부 프리미엄 모델(GPT-5, Claude, Gemini 등)을 자동 라우팅으로 운용합니다.
– 질문 유형에 맞는 모드 선택(Quick/Pro/Deep Research)과 포커스 모드(학술/Reddit/YouTube)가 활용의 핵심입니다.
– 어떤 AI 도구도 100% 정확하지는 않습니다. 인라인 인용을 직접 클릭하여 원문을 확인하는 습관이 AI 시대의 가장 중요한 정보 리터러시(Information Literacy, 정보를 비판적으로 평가하고 활용하는 능력)입니다.